In the media these days, Artificial Intelligence (henceforth AI) is making a comeback. Kevin Drum wrote a long piece for Mother Jones about what the rising power of intelligent programs might mean for the political economy of the United States: for jobs, capital-labor relations, and the welfare state. He worries that as computer programs become more intelligent day by day, they will be put to more and more uses by capital, thereby displacing white-collar labor. And while this may benefit both capital and labor in the long run, the transition could be long and difficult, especially for labor, and exacerbate the already-increasing inequality in the United States. (For more in the same vein, here’s Paul Krugman, Moshe Vardi, Noah Smith, and a non-bylined Economist piece.)
The clearest academic statement of this genre of writing is Erik Brynjolfsson and Andrew McAfee’s slim book Race Against The Machine. Brynjolfsson and McAfee suggest that the decline in employment and productivity in the United States starting from the 1970s (and exacerbated by our Great Recession of 2008) is a result of too much technological innovation, not too little: specifically, the development of more powerful computers. As they say, “computers are now doing many things that used to be the domain of people only. The pace and scale of this encroachment into human skills is relatively recent and has profound economic implications.” To bolster their case, they introduce a variety of examples where programs are accomplishing intelligent tasks: machine translation, massive text discovery programs used by lawyers, IBM’s Watson and Deep Blue, the use of kiosks and vending machines and on and on. They end the book with a set of suggestions that would surprise no one who reads economists: more redistribution by the state, an education system that increases human capital by making humans partners with machines rather than their competitors, adopting a wait-and-see approach to the many new forms of collaboration that we see in this digital age (crowd-sourcing, the “sharing economy” etc.) and a few others.
Curiously though, Race Against the Machine has very little to say about the innards of this technology whose rise concerns the writers so much. How or why these programs work is simply not relevant to Brynjolfsson and McAfee’s argument. Usually, their go-to explanation is Moore’s Law. (Perhaps this is another way in which Moore’s Law has become a socio-technical entity.) To answer the question “why now,” they use a little fable (which they credit to Ray Kurzweil). If you take a chessboard and put 2 coins on the first square, 4 on the second, 16 on the 3rd and so on, the numbers start to get staggeringly large pretty soon. They suggest that this is what happened with AI. Earlier advances in computing power were too small to be noticed – but now we’ve passed a critical stage. Machines are increasingly going to do tasks that only humans have been able to in the past.
If, as an STS scholar, this explanation sounds a bit like hand-waving to you, I completely agree. How might one think about this new resurgence of AI if one thinks about it as a historian of technology or a technology studies scholar rather than as a neo-liberal economist? In the rest of this post, I want to offer a reading of the history of Artificial Intelligence that is slightly more complicated than “machines are growing more intelligent” or “computing power has increased exponentially leading to more intelligent programs.” I want to suggest that opening up the black-box of AI can be one way to think about what it means to be human in a world of software. And by “opening up the black box of AI,” I don’t mean some sort of straight-forward internalist reverse-engineering but rather, trying to understand the systems of production that these programs are a part of and why they came to be so. (In this post, I won’t be going into the political economic anxieties that animated many of the articles I linked to above although I think these are real and important – even if sometimes articulated in ways that we may not agree with.)
[Image Removed by Mother Jones] Terrified woman and water-drinking robot. Image from Kevin Drum’s piece in Mother Jones.
With that throat-clearing out of the way, let me get into the meat of my argument. Today, even computer scientists laugh about the hubris of early AI. Here is a document from 1966 about what from Seymour Papert calls his “summer vision project“:
The summer vision project is an attempt to use our summer workers effectively in the construction of a significant part of a visual system. The particular task was chosen partly because it can be segmented into sub-problems which allow individuals to work independently and yet participate in the construction of a system complex enough to be real landmark in the development of “pattern recognition”.
One summer to create a system “complex enough to be a real landmark” in pattern recognition! Good luck with that!
Even back then, AI was not a static entity. Papert’s approach – which was the dominant one in the middle of the 1960s – was what Mikel Olazran calls “symbolic AI.” Essentially, in this approach, intelligence was seen to reside in the combination of algorithms, knowledge representation and the rules of symbolic logic. Expert systems that were built in the 1980s (and about whose “brittleness” Diana Forsythe has written memorably about) were the culmination of symbolic AI. These were built by AI experts going out and “eliciting knowledge” from “domain experts” through interviews (although as Forsythe points out, they would usually only interview one expert), and then crafting a series of intricate rules about what they thought these experts did.
The other approach was connectionism. Rather than linguistically-rendered rules constituting thought, connectionists suggested that thought came out of something that looked like a bunch of inter-connected neurons. This research drew extensively from the idea of the “perceptron” that Frank Rosenblatt conceived in the 1950s, and to the ideas of feedback in cybernetics. Perceptrons were discredited when Papert and Minsky, the leaders of the symbolic AI faction, showed that perceptrons could not model more than simple functions, and then revived in the 1980s with the invention of the back-propagation algorithm by Rumelhart and McLelland. As Olazaran shows, the perceptron controversy (i.e. the way perceptrons were discredited and then revived) is an excellent test-case for showing that science and technology in the making allow for a great deal of interpretive flexibility.
The revival of connectionism led to more and more interest in using statistical methods to do intelligent tasks. Today the name that computer scientists use for these methods is “machine learning” (or sometimes “data mining”). Indeed, it is machine learning that is at the heart of many of the programs discussed by Brynjolfsson and McAfee (and interestingly enough, the phrase does not appear at all in the book). The question of how this shift of interest to machine learning happened is open. Perhaps it was because funds for symbolic AI dried up; also, corporations had, by this time, started to increasingly use computers and had managed to collect a significant amount of data which they were eager to use in new ways. I, for one, am looking forward to Matthew Jones’ in-progress history of data mining.
The difference between machine learning/connectionist approaches and symbolic AI is that in the former, the “rules” for doing the intelligent task are statistical – expressed as a rather complicated mathematical function – rather than linguistic, and generated by the machine itself, as it is trained by humans using what is called “training data.” This is not to say that humans have no say about these rules. Indeed, many of the decisions about the kinds of statistical methods to use (SVMs vs. decision trees, etc.), the number of parameters in the classifying function, and of course, the “inputs” of the algorithm, are all decided by humans using contingent, yet situationally specific criteria. But while humans can “tune” the system, the bulk of the “learning” is accomplished by the statistical algorithm that “fits” a particular function to the training data.
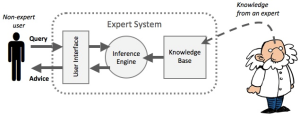
Expert systems as the culmination of symbolic AI. The “intelligence” of the system consists of rules that constitute the “inference engine” that embody the way the expert works. Image taken from this article.
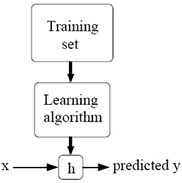
In machine learning and connectionist approaches, the “intelligence” resides in a mathematical function that is learnt after feeding the algorithm “training” data. Image taken from this article.
I want to suggest that the rise of machine learning was accompanied by three institutional changes in the way AI research was done: first that researchers stopped worrying about the generalizability of their algorithms and concentrated on specific tasks. Second, they concentrated their efforts on building infrastructures through which machine learning algorithms could be scaled and used as off-the-shelf components. And finally, they turned to networked computing itself to combine these machine learning algorithms with human actors. (The culmination of these is crowd-sourcing which is both a source of data for machine learning algorithms, as well as part of a scaled machine learning architecture to accomplish tasks using both humans and machines.)
AI practitioners today – in particular, machine learning researchers – are perfectly willing to be practical, to concentrate on particular domains rather than look for general purpose laws. For instance, consider this definition of machine learning given by Tom Mitchell (the author of a canonical textbook on the topic) in a piece written in 2006 – one of those pieces where the giants of the field try to set out the outstanding research problems for young researchers to solve.
To be more precise, we say that a machine learns with respect to a particular task T, performance metric P, and type of experience E, if the system reliably improves its performance P at task T, following experience E. Depending on how we specify T, P, and E, the learning task might also be called by names such as data mining, autonomous discovery, database updating, programming by example, etc.
Researchers concentrate on coming up with practical definitions of T, P and E that they can then proceed to solve. Back when I used to be a computer scientist designing algorithms to detect “concepts” in video, my adviser used to complain when IBM researchers designed classifiers to detect concepts like “Bill Clinton” or “Hillary Clinton.” His point was two-fold: first, that designing a classifier to detect “Bill Clinton” in a video was not good science because it in no way advanced the research agenda of detecting concepts in video. But, and second, IBM would do it anyway because it could (it had the resources) and because it would be useful.
Recently, Noam Chomsky criticized this tendency of AI researchers to use probabilistic models in computational linguistics. Probabilistic models were fine, Chomsky suggested, if all you wanted to do was make Google Translate work, but they were not real science, they were not causal. In response, Peter Norvig (co-author of the famous textbook on Artificial Intelligence and the director of research at Google) replied that probabilistic modeling works – and in a way that those elegant theories of the General Problem Solver never did. And Norvig goes even further in advocating that computer scientists not worry too much about generalized theories – because nature, he suggests, is far too complicated for that. (I really recommend reading Norvig’s response to Chomsky since it’s a kind of debate that computer scientists rarely have.)
The second factor is scale. Computer scientists have concentrated a lot of effort in these past few years to build infrastructures that make machine learning easier. This includes black-boxed, off-the-shelf, versions of these algorithms that can simply be trained and used. It also includes massive frameworks in which these algorithms can be coupled to each other and multiplied to build more and more complicated systems. So for instance, you connect a 1000 classifiers together (one for Bill Clinton, another for cars, etc.), and the result is a powerful system that can be used for “intelligent” tasks in video concept detection (“find all clips in videos where Bill Clinton is driven around” for e.g.). IBM’s Watson is exactly an example of such a massively scaled system – scaled to almost unimaginable levels solely so that it could match the human challengers in a particular task i.e. Jeopardy. In Watson there are classifiers whose output trains other classifiers and on and on.
The third factor is, I think, the most interesting. Machine learning researchers do not really expect their algorithms and programs to do all the work. Rather, they see these algorithms as working with humans, who might supervise them, tune them, provide them with data and interpret their results and so on. They seem to have taken to heart Terry Winograd’s final recommendation at the end of Understanding Computers and Cognition, in which he actively disavowed the symbolic AI that he had worked so hard to create, and instead suggested that computer scientists concentrate on designing useful assemblages of humans and computers rather than on creating intelligent programs. This is brought out beautifully in Alexis Madrigal’s recent story about Netflix’s recommendation algorithm. Briefly, Madrigal set out to find out how Netflix’s quirky genre system (Scary Movies Based on Books, Comedies Featuring a Strong Female Lead, etc., 76,897 micro-genres in all) is generated. The answer: through a combination of humans and machines (again, nothing new here for STS scholars). First, the Netflix engineers spent a few years creating recommendation engines using predictive algorithms that trained on the “ratings” that users provided before deciding that viewer ratings alone were not enough. They then started to employ people who “code” a movie (in terms of genre, etc.) based on a rigorous how-to manual that Netflix has created, especially for them. This movie-categorization was then combined with the ratings of Netflix viewers. By actively clustering both of these in some mathematical space, and then interpreting the clusters that result, they produced the quirky genres that Netflix has since become famous for. This is not a bad example of how AI is put to work today in systems of production. (It’s a pity that Madrigal focuses his attention so relentlessly on the specific recipe used to create the Netflix genres because his account offers fascinating glimpses of a whole host of behind-the-scenes work going on at Netflix).
These three factors – creating probabilistic machine learning classifiers for concepts without worrying about their generality, creating and using massive infrastructures to combine and mix-n-match machine learning algorithms, as well as combining the outputs of humans and machines in carefully human supervised ways – it seems to me that these explain better the revival of AI, as well as the reason why many people fear its political-economic implications. I will admit upfront that this is a mostly internalist story of what is happening and boils down to “Programs are being trained to do really particular tasks using data (perhaps specially created!) and then combinatorially combined in ad-hoc ways.” But I hope that it is a little more complicated than “computer power has increased by leaps and bounds” or “machines are getting more and more intelligent” (although neither of these are necessarily inaccurate). What I really hope is that it will help us think through the political economic implications of the new AI. And that, perhaps, is a subject best left for another day (given the length of this blog-post!).

{kind=link}
9 Trackbacks