(Almost) everyone makes data. People browsing the internet or buying stuff generally do so without knowing much about the data that their activities generate, or even knowing that they are doing so. Scientists, though, are supposed to be a little more conscientious about the data they collect, produce, share and borrow (at least in their professional capacities). They’re lately supposed to be, among other things, data managers. This is largely the product of the funding and institutional environments; program officers, science managers, and university administrators increasingly demand rationalized, comprehensive data management plans (DMPs) from researchers. In many cases, such as those from the NSF, these demands include requirements to store data for a specific period of time—often five or ten years beyond completion of the project—and to make such data publicly available. For some scientists, this is just a formalization of existing disciplinary best practices. For many, though, and for anthropologists who study them, these injunctions raise critical epistemological questions about the nature of data, and by implication, of contemporary scientific inquiry—anthropology included.
Managing what, exactly?
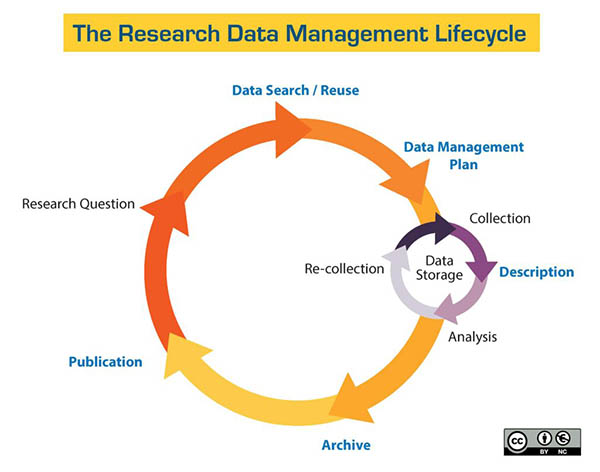
Typical research data management flow chart. From University of Santa Cruz Library. Creative Commons 3.0.
Given their need to address a huge range of sciences, with concomitantly diverse forms of data, these mandates are often left quite vague; in consequence, the responsibility for developing best practices devolves to the individual researcher, who must often turn to their local institution for support. For researchers used to dumping inscriptions on external hard drives and sharing them—maybe—with close colleagues already interested in their research, these demands produce practical challenges. What are acceptably robust and redundant archival practices? What counts as “publicly available”? How am I going to pay for all of this, when my data spirals into the terabytes?
Currently, I’m doing some research as part of a team from Fondren Library at Rice University to find out how faculty are answering these questions, and how the library might help them find better answers. While this work is applied in its aims, it has also been raising thornier epistemological issues, turning on how scientists make the determination that a given set of inscriptions is “data,” and fit to be shared.
So far, I’ve been pleasantly surprised by how widespread the realization is that “Raw Data” is an Oxymoron in the natural sciences. Most people who think about these things professionally seem aware that data are always already cooked by the very act of their inscription in a particular recording substrate and within a particular sociotechnical system. Of course, we quickly find that some data are a great deal more rare than others; some are par-boiled, some are overcooked. Sometimes this is by accident, and sometimes by choice. There is a huge variety of approaches to cooking data, suited to different occasions and different contexts. Some data are expertly and elegantly prepared, fit to be shared or even potlatched with a wide community of fellow researchers; others are more akin to shift meals, nourishing but proper to the kitchen and the very workers who have produced them, rather than being polished for the dining room. Far from being academic, it seems to me that the culinary question is shared by practitioners and second-order observers alike: it strikes to the core of what counts as the “data” in “data sharing and archiving.” What needs to be stored, what can be profitably exchanged?
The pertinent questions, then, might be where and when, rather than what, are data. At what stage of inquiry, of cooking the world, can we say that “data” proper have emerged? Certainly, not everything that researchers or their machines write down is an accurate or useful tracing of that world. Some of it—sometimes a great deal of it—is noise, not raw, but instead spoiled data. Calibration runs, improperly executed assays, forged or censored archival materials, interviews that turn into press conferences; all produce unsavory data. Ultimately, sorting out the data fit to be cooked is a question of disciplinary, and of local, expertise. Researchers need to know their systems, fields, and colleagues well enough to judge the comestibility of a given datum. Do we share the direct output from our radioimmunoassays, or do we share a cleaned and coherent set of curves? Do we share our informants unedited open-ended survey responses, or do we share coded tabulations?
For their part, it seems that researchers in the majority of fields don’t actually want access to their colleagues’ rarest data. If they’re interested in anything other than the final product, they’re interested in data that’s been cleaned and selected by those who know the experimental system well enough to determine whether it’s useful or not. Perhaps what we ought be sharing is akin to a “deconstructed” plate: individual components of data that have been processed, but not assembled into a final, fixed form. The idea, then, would be that colleagues cum diners could reassemble things in new and interesting ways that might reveal hidden nuances of flavor. Of course, though, there remains some interest in seeing what’s going on in the kitchen: funding agencies, as well as editors and reviewers, ideally, want access to the entire process whereby raw data is carved out of the world and turned into cooked analysis. Such functions of verification are all well and good. It seems to me, however, that the more important shifts produced by bureaucratic demands will be found rather in the disruptions they produce in the collaborative process of discovery itself.
Teaching anthropologists to share
In my work as an applied researcher with the Rice library, my concern is to help people who are already ready and willing to share and archive their data figure out how best to do so. It has also made me a fair bit more interested in what the ongoing push to share and store research data better might mean for our discipline. Anthropologists, with some notable exceptions, have been anxious about injunctions to share data. Some of the most frequently heard corridor-talk concerns, though, seem to me rather jejune or even naive. The idea that our responsibility to protect our informants and safeguard their data is unique among the social and behavioral sciences shows a singular arrogance and misunderstanding of our colleagues’ work. Further, and more embarrassingly, it seems to stem from the rather precious idea that our method is so singular, even mystical, that the data it produces demand forms of ethical attentiveness which could only possibly be maimed by their encounter with dread, lifeless bureaucracy. We seem to come to discussions about data sharing with a chip on our collective shoulder about methodology.
There are, however, real—or at least more interesting—problems for anthropology when it comes to sharing data: we may not be the best cooks. That is to say, I have a sneaking suspicion that most of our notes are worse than useless to other people (mine certainly would be). In part, this is due to a lack of orthographic standards, i.e., best practices for capturing the imponderabilia of daily life in shorthand text (the laudable efforts of people like Brenda Farnell notwithstanding). This seems part of a larger reluctance in some quarters to spend adequate time training graduate students in methods. The idea seems to be that students need to figure out what works for them in their specific inquiry and field site. To my mind, though, this is more the result of inertia and a romantic understanding of lone wolf fieldwork and the magic of ethnography than any considered pedagogical strategy. This seems like it might be profitably figured as an institutional and technical problem, though, and we could easily imagine it being addressed as such, especially given the plethora of collaboration and document management technologies available today.
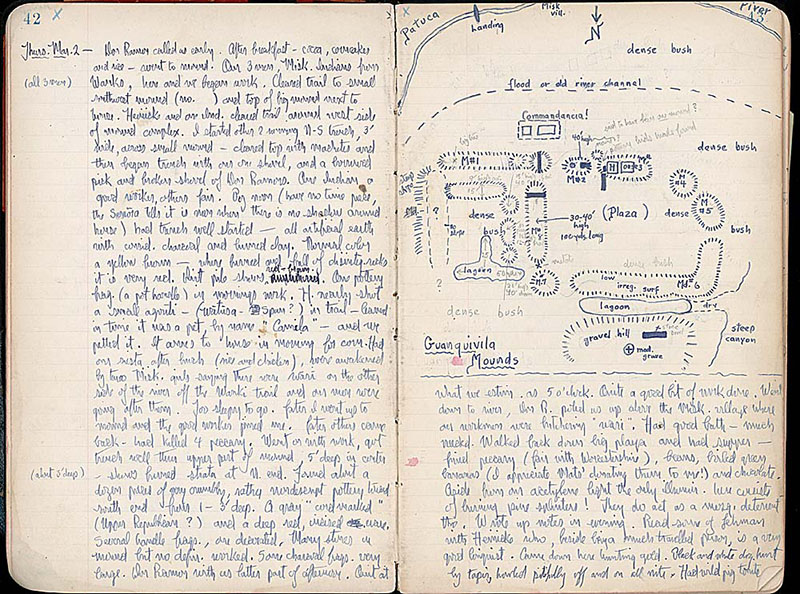
Excerpt from William Duncan Strong’s field journals (Honduras, 1933). From the collections of the Smithsonian Institution.
There is another problem with data sharing in anthropology, though, that is more epistemological: our notes function differently than, for example, survey data, in that they are both data in themselves and a guidebook for the data inscribed in the brain of the fieldworker. The work of ethnography is, and will remain, a work of evocation: of bringing out a world from within the experiences of the ethnographer as instrument. Unlike Stephen Tyler, however, I don’t think that there’s anything constitutively mystical about this mental data or the process of evocation that operates upon it. They are just data that have been inscribed in the substrate of a brain going through the experience of participant observation, rather than data produced by a machine encountering a sample, or a survey encountering a human, for example.
Can sharing data be exciting?
It seems to me that the daring response to injunctions to share data would be to take them at their word, to approach the sharing of mental data as a technical problem rather than an insurmountable metaphysical obstacle. How might we build shared spaces of inquiry that produce reliably similar mental inscriptions of the world? How can we write together? How can individual researchers produce shareable, useful documents that are somewhat less rare than our fieldnotes without being as cooked as ethnography itself? Approaching the problem in this way, I think, has the potential to be more revolutionary that the standard anthropological trope of making the familiar strange. I’m all for being provocative, and for forcing people to examine the assumptions upon which their work and lives are based. However, I think that anthropology here needs to be wary of being too untimely to have a say in the contemporary.
To put it simply, data sharing and collaborative research are here to stay. If we are interested in continuing to receiving respect and funding for an even notionally scientific approach to the study of human diversity, we’re going to have to figure out how to do them, and how to make them work within the disciplinary structures of anthropology. That said, I’d like to think that there is room to bring our particular culinary flair to the cooking of data in other disciplines as well. Models for such thought exist: from the phenomenological sociology of Schütz, to the collaborative experience of projects like the Asthma Files and Matsutake Worlds, or even the drier but no less fruitful methodological inquiry of folks like H. Russell Bernard, there are people working to open up the experience of fieldwork and the data it produces to lateral engagement with other scientists. The pressing task confronting researchers today, it seems, is to leverage the experimental dynamics and potentially revolutionary potential of such work from our unique place within the broader science system, rather that quailing in the face of bureaucratic injunctions to share and manage our data.
