2014 was the year that the major players in qualitative data analysis (QDA) software released native versions for the Mac. For me, the timing was perfect: my dissertation fieldwork in North Dakota had drawn to a close by summer’s end, and my advisor was encouraging me to roll up my sleeves and start working through my material. I wasn’t sure which software package would serve me best, though, and most of the guidance I could find around the Web declined to make head-to-head comparisons. Then, too, I was mindful of the critiques charging that QDA software of any stripe contributes to the mystification of method and amounts to an overpriced means of avoiding index cards, glue, and scissors. I have nothing against index cards, but with operating system issues off the table and student licenses available for under $100, I decided to see if one of these tools could help me to organize my data and get writing.
After sizing up the available options, I downloaded trial versions of two well-known QDA products: NVIVO and Atlas.ti. I knew I was looking for an attractive and intuitive user interface that would allow me to code data in multiple formats: handwritten field notes, interview transcripts, documents I collected in the field. I had little faith that calculating the frequency and co-occurrence of the codes I assigned would unlock some deep, hidden structure of my material. But, taking a cue from one of the founding texts of software studies, I resolved to approach QDA software as an object that “deserves a reciprocation of the richness of thought that went into it, with the care to pay attention to what it says and what it makes palpable or possible.” How, I wondered, would my choice of software package make some kinds of analytical thinking possible and forestall others? What would my choice commit me to?
Based in Australia and descended from a legacy product called NUD*IST, NVIVO uses the language of sources and nodes to organize research data. A source might be an interview, a report, or a memo that the researcher composes during the coding process. A node is harder to define: it can refer to a thematic code assigned to a portion of a source, like “skill” or “debt.” But NVIVO also has a special type of node called a case node, which can be used to represent people, organizations, or other discrete entities with definable attributes. While the online documentation brackets the question of what these entities ought to be understood as cases of, I want to suggest that the case node is a site for thinking through the relationship between the singular and the general in our research imaginaries. A 2007 special issue of Critical Inquiry reflected on what is at stake when a particular idea of a person or norm of personhood subtends the logic of the case. The case node can thus be seen as an occasion for asking, as Lauren Berlant does in her introduction to the issue, what does it matter who one is?
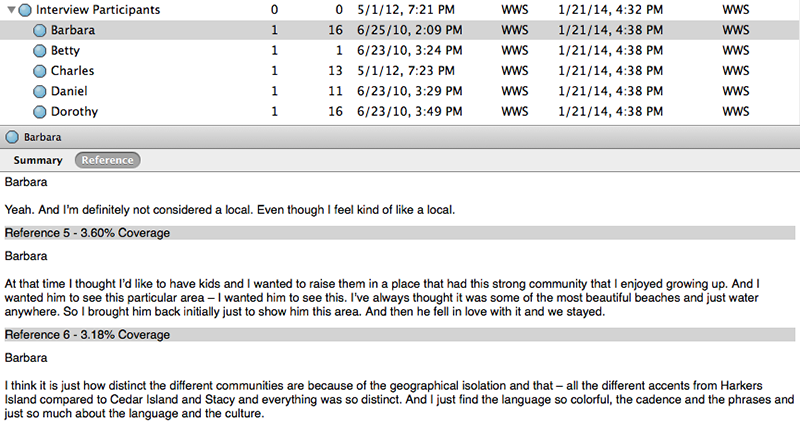
Let’s look at how case nodes work at the level of the software. In the screenshot above, we see a list of participants in the sample study provided by NVIVO. Barbara, Betty, and Charles can be associated with entire sources (as in an interview) or with a portion of a source (as in a passage of field notes, or a reference in an interview with someone else). NVIVO can then retrieve whatever data is associated with each participant.
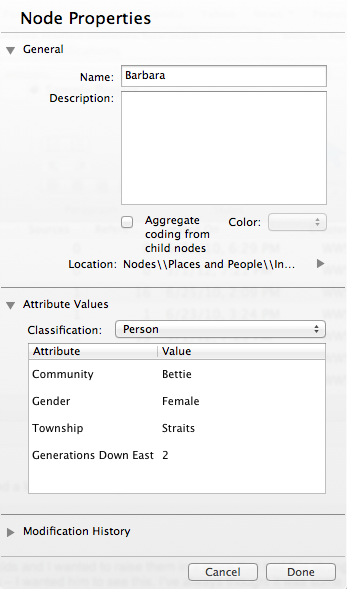
But, because case nodes are also associated with demographic attributes, it’s easy enough to construct population-level queries: what, for instance, did female participants including Barbara say or do in conjunction with one or another thematic code? The architecture of the case node strikes me as friendly to ethnographers, because it acknowledges that we are interested in people both as individuals with whom we have specific, noninterchangeable relationships and as instances of broader categories. Case nodes allow us to move between these scales of analysis.
Headquartered in Berlin, the developers of Atlas.ti have taken a different approach. The grammar of the software is similar enough to NVIVO: sources become documents, which can include video and audio files, and a separate memo function. Nodes in NVIVO become codes in Atlas.ti, which can be associated with an entire document or with just a portion, which is called a quotation. Codes can be nested in groups, and combinations of codes can be saved as a smart code. But the code as a basic unit is less supple than the node: there is no way of associating it with additional attributes, and so the linkages it makes extend along only one axis.
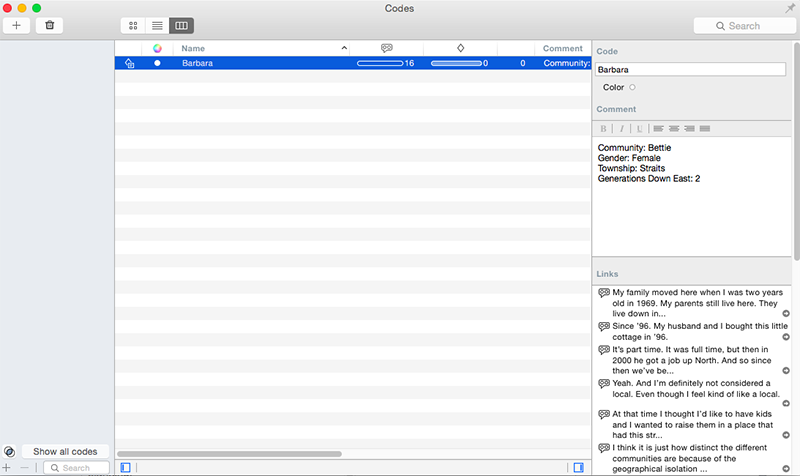
As a result, there’s really no way for Barbara as a person, both singular and general, to exist inside Atlas.ti. I can create a code for Barbara, which would gather the various references to her across all of my documents. But all I can do with her demographic information is to type it into the comment field, which can’t be queried. Assuredly, there are other ways of working with demographic categories in Atlas.ti; it’s just that Barbara qua Barbara disappears from view. Following Berlant, we might approach this limitation in the software as an opening in thought demanded by a different model or valuation of the person. For instance, reading Eduardo Kohn’s How Forests Think means reckoning with selves that exceed the skin-bound organism. It might have been useful for Kohn to code for selves like these and then to track which living forms they take. Yet the gender, age, and kinship ties of Kohn’s human interlocutors also matter, since those attributes cinch up with the relational selves of the forest in different ways. It is not clear that the case logic of Atlas.ti would have suited Kohn’s ethnographic data any better than my own.
In the end, of course, it couldn’t all hinge on Barbara. The Mac versions of both software packages were released without all of the functionality of their Windows counterparts, and so choosing between them involved reading the tea leaves of their respective development roadmaps (NVIVO | Atlas.ti). Some missing features, like support for creating interview transcripts in Atlas.ti, are due to be rolled out in the next few months. Other differences are likely to persist: it is easier to import a project into NVIVO than to export it to another program, while Atlas.ti offers universal data export and has a stated commitment to interoperability. For me, the differences in user interfaces were finally what tipped the scales toward Atlas.ti. NVIVO for Mac looks and feels like a Windows program, right down to the yellow folder icons. The flip side of its customizability is a sense of being overengineered, which manifests itself in tiny aggravations: why, for instance, force users to click Edit every time before starting to code a source? In contrast, Atlas.ti for Mac looks restrained, even sleek, and quickly feels familiar. In building the Mac version from the ground up, the developers of Atlas.ti have been given a chance to strip away some of the feature bloat that may scare researchers off of QDA software in the first place.
As new features are added, though, it’s safe to say that the case node won’t be one of them. Nowhere in the Atlas.ti documentation I reviewed could I find an example of a code structure that included the names of individual informants. It is as though the analytic imaginary that has grown up around the software is one in which wanting to connect data to persons is inconceivable. So those of us whose research methodologies insist on those connections will have to get creative: perhaps we can use code groups to associate persons with demographic attributes once the Mac version allows them to serve as global filters, or perhaps we can come up with workarounds that exist outside Atlas.ti altogether. Regardless, the problem of who Barbara is underscores the importance of taking software and its affordances seriously, recalling that our tools are never neutral and asking how, inevitably, they shape the intellectual work we do.

8 Comments
This review omits the one contender that has actually released a truly fully-functional version of its software on the Mac OS platform: MaxQDA. I have long used NVivo (mainly because they were the first to develop the ability to analyze, annotate, and code digital audio when I needed it most – in the dissertation project), but this commitment to releasing a truly comparable Mac OS version of the software is swaying me towards MaxQDA. If you use F5 (on Mac, F4 on Windows) to transcribe your stuff, then Max QDA also imports those transcripts, live hyperlinks to the audio and all. It adds quite a bit to the workflow of ethnographic data analysis.
I am still tied to my virtual machine to run Nvivo since the Mac version of Nvivo barely fits the qualities of a beta-release (I was a beta tester, and at that phase it was more like an alpha version of the software). I like Nvivo when they get things right – the power and flexibility to do what one wants is nice, but they tend to release stuff before working out all the kinks. The MaxQDA developers, however, seem to be more on the ball with regards to getting stable and complete versions of their software to market. And their development now parallels just about anything one can do in Nvivo and Atlas. At any rate, thanks for the review.
Another point worth considering along the lines of how the “choice of software package make[s] some kinds of analytical thinking possible and forestall[s] others”, one thing these packages CAN do that index cards and scissors CAN’T is enable one to interact directly with the digital media (or a digitization of the media) that captured the original ethnographic moment. I found in analyzing my dissertation data that working directly from the audio of an interview was much more productive than working off of a transcript. I ended up transcribing a lot of the material as well, which is worth the effort for particular ends, but the ability to track one’s analysis of the audio or video collected in ethnographic research enables a new dimension of the write-up process.
This was very informative, thank you! I am a Windows user and I remember giving up on Nvivo almost immediately since I found the Atlas.ti interface far less clunky to use (also I remember thinking that Nvivo had an unnecessarily abstruse terminology).
Your post is the first I’ve heard of the “case node” feature (which sounds very useful indeed!). If you come up with other ways of incorporating this kind of case-node type analysis in Atlas.ti, I’d love to know!
Hi Marcel,
thank you for your thoughtful article, and your praise of the user interface of ATLAS.ti for Mac.
As the lead developer of ATLAS.ti for Mac, it is great to see that the care we put into making this a real, native Mac application really pays off for our users. Making a powerful program feel simple and delightful is an art form, and my team is working very hard to fight the constant lure of “just one more button”. That said, we are adding new features or improvements to existing ones in almost every release, based on customer feedback as well as our internal roadmap.
I really enjoyed your comments on our shortcomings as well, particularly the attribute system and the annotation of documents themselves. We’ve given this some thought ourselves, but we want to get it right – It really comes down to balancing features and usability. Feedback “from the trenches” like yours helps us find this balance.
Thank you, and have a great new year!
I very much appreciate this post, and it is very timely for me. I was poised to update MaxQDA for my Mac so it is good to hear some alternative perspectives and commentary. Thanks for this post!
Hi Marcel
Thanks for your article. It has been an interesting year in QDA software for Mac users, I know there has been a long and much anticipated wait for these releases.
I am the Product Manager of NVivo and I just wanted to raise with you that there was a mistake with one of the points you made against NVivo for Mac.
“The flip side of its customizability is a sense of being overengineered, which manifests itself in tiny aggravations: why, for instance, force users to click Edit every time before starting to code a source?”
This is not correct. A user of NVivo for Mac doesn’t need to click Edit before starting to code a source. The Edit functionality is there only if the user wishes to make edits to the content of the source. I think it is important to point out, because I agree, it would be painful if you needed to click Edit prior to coding, however that is not the case.
I’m glad you agree that it is important to many ethnographers who Barbara is, we also think that the ability to apply demographic information to Cases is where some of the real power of NVivo comes through.
Just a reminder. TAMS Analyzer has been mac native from soon after 9/11 (when I first started a project on the anthrax attacks), is free, and developed by early CASTAC member Matthew Weinstein!
That’s what I used to code my dissertation fieldnotes, but I didn’t get as far as figuring out how to use it for further analysis. Any tips?
Wonderful post – v. helpful to see the discussion of Kohn, which highlights what seems to be (as you suggest) Atlas.ti’s biggest shortcoming for ethnography, the difficulty of assigning and searching/querying document-level variables/attributes.