Editor’s Note: This is the inaugural post for the Law in Computation series, a collection of blog posts from faculty and graduate student fellows at UC Irvine’s Technology, Law and Society Institute. Leading up to a summer institute in 2018, the series provides examples of research and thinking from this interdisciplinary group and elaborates how sociolegal scholars might address new computing technologies, like artificial intelligence, blockchain, machine learning, autonomous vehicles, and more.
In 2015, a robot buying illicit items off the “dark web” was confiscated by the Swiss authorities along with its haul of Ecstasy pills, a Hungarian passport, counterfeit designer clothing, and other items. Dubbed Random Darknet Shopper it was a bot programmed to shop on the dark web using Bitcoin, the pseudo-anonymous cryptocurrency that, at the time of my writing, is experiencing an enormous bubble. Previously assumed to be the domain of criminals or drug dealers, the Bitcoin bubble has made it more mainstream, even on popular television shows like The Daily Show and is being discussed at policy forums worldwide. It increased in value from just over $1000 to over $8000 between February 2017 and February 2018, with a peak at over $19,000 in mid-December 2017. While it was pretty obscure just a few months ago, you probably have a cousin or uncle currently “mining” Bitcoin or trading in similar digital tokens whether you know it or not.
The bot had all its purchases delivered to the Kunst Halle St Gallen art gallery, which were put on display and constituted the totality of the installation. After having confiscated the material, the authorities returned everything but the Ecstasy, even though the public prosecutor held “that the possession of Ecstasy was indeed a reasonable means for the purpose of sparking public debate about questions related to the exhibition.”

Gallery showcasing Random Darknet Shopper’s haul. © Tom Mesic
I started studying Bitcoin with Taylor Nelms and Lana Swartz in 2011, two years after it had been launched in 2009. We were in a café working on something else, when a colleague at the US Agency for International Development (USAID) emailed asking if I knew anything about it. I forwarded her message to a friend at the Fed. Thus began our journey (and no, we haven’t gotten rich!). We were interested in what Bitcoin meant for money, how it fit into the landscape of electronic payment platforms like Visa, and how regulators responded. We watched people discover other possibilities in Bitcoin’s underlying decentralized database structure, called the blockchain. By 2014 our interlocutors were increasingly talking about programs run on top of a blockchain that would execute automatically when certain conditions were met—which they called “smart contracts.” As someone trained in the anthropology of law, all this talk of contracts made my legal anthropology brain kick in.
In 2015, I received a grant from the NSF to study this migration of blockchain technology from “money” to “law.” The goal was to see how coders, promoters, investors, regulators, and lawyers were understanding this notion of law being “in the code.” My colleagues and I published a few papers, including a preliminary one on smart contracts. Why were people imagining these strings of computer commands as a contract? Why not just call them “programs,” I wondered? Getting that initial taste of how people involved in this new technology were starting to intrude into the legal domain set the stage for what came next.
Outside my small circle of colleagues who had been steeped in blockchain since the beginning, however, I had a really hard time explaining what I was doing. I’d have to start from square one, explaining what blockchain is, how it works, what it can and can’t do. I started to feel like an IT consultant. The media started calling, too, asking me to do much the same work—everyone from Bloomberg to TopProducer (a publication for the agriculture industry).
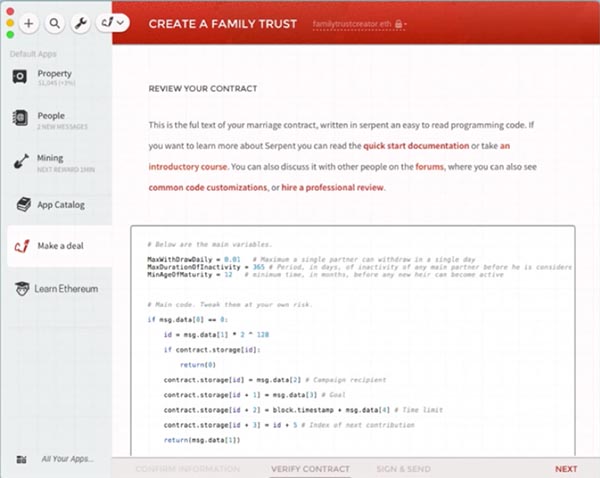
A “smart contract,” discussed in DuPont and Maurer 2015: http://kingsreview.co.uk/articles/ledgers-and-law-in-the-blockchain/
I started noticing other intersections of coding, law and money, instances of algorithmic governance where the machines seem to be making legal decisions. In 2015, several cities legally challenged an app that used data analytics to help drivers contest parking tickets. In 2016 a man was killed during Tesla’s test of its autopilot driving system, heightening the debate over legal liability for driverless cars which had already been roiling the insurance industry. ProPublic’s series on Machine Bias covered new developments in policing, surveillance technologies, user-generated data, DNA databases and how machine learning is shaping decisions about the allocation of resources and force. Entrenched biases based on race now have a sort of algorithmic cover and the irrefutability of having come from “the code,” not to mention the legal protection of having been derived from proprietary software. The City of New York just passed a bill protecting its citizens from “algorithmic discrimination.”
Lawrence Lessig argued in his 1999 classic, Code and Other Laws of Cyberspace, that computer code was usurping the place of law. Code, he foresaw, would determine privacy, property, speech, indeed all that most modern Western peoples had heretofore sought to regulate through law. Yet it could and should be regulated, he argued, and brought under the domain of real-world law and governance.
There is a lot of technoutopian excitement about artificial intelligence and other new computing technologies, from autonomous vehicles to Alexa to, yes, Bitcoin. How can those of us who study law from a social sciences and humanities perspective get a handle on phenomena such as these, digging into the inner workings of algorithms and other new computational technologies without falling for the hype?
We are launching a Technology, Law and Society Summer Institute at UC Irvine this June to begin to address these questions. The model is the Law and Society Association’s now defunct Summer Institute. From 1992 until 2007, the Law and Society Association sponsored annual gatherings to train new sociolegal scholars. When the institute started, law and society research was still a renegade space. Challenging years of dominance of doctrinal approaches coming out of the law schools, social scientists were questioning the politics of law, law as a cultural process and law as constitutive of identity. New legal entities were being fought over in the courts—new forms of property, like intellectual property and property in organs or cell lines or biological materials. And the differential distributional effects of supposedly neutral juridical procedures like stare decesis—the doctrine of following precedent— were demonstrated to reflect class, race, and colonial power relationships. Law was not pure or transcendent. Law was thoroughly social and needed to be understood in action.
Sociolegal scholars in conventional social science departments found that their colleagues just didn’t understand why they were “playing at doing law” when they often didn’t have JDs and weren’t in law schools. In short, it was a lot like the situation of science, technology and society (STS) scholars—often not trained as lab scientists, how and why were they imposing on the domain of science, and how were their questions relevant to disciplines historically defined by a very different set of objects?
The Law and Society Summer Institute nurtured fledgling scholars and incorporated them into a vibrant interdisciplinary community in order to reproduce and institutionalize law and society research. It worked! Over the course of its existence, the institute had 117 faculty and 274 students, and forged a generational cohort of sociolegal scholars. It received partial funding from the National Science Foundation. Last year, I was having a conversation with then-NSF program director Scott Barclay. We were musing, what if the summer institute were held today? What new legal challenges and issues will sociolegal scholars be facing and what training would they need?

A tiny sliver of code from a Twitter-bot. Source: https://www.pygaze.org/2016/03/how-to-code-twitter-bot/
If the old problem was moving from law on the books to law in action, the new problem might be the shift from law in action to law in computation. Machine learning, artificial intelligence, the Internet of Things, advances in robotics, autonomous, automatic computational systems that do things humans used to do—including legal reasoning and decision making, including policing, including regulation—all of these developments now matter consequentially in the everyday life of legal practice.
UC Irvine has a tradition of successfully training interdisciplinary sociolegal scholars. We have also enjoyed some remarkable collaborations between social and computer sciences. Why not take advantage of the infrastructure here and try to imagine a Summer Institute for the computational age? With Mona Lynch and a number of others on campus, we proposed to do just that. The NSF generously funded it as a pilot project. And we are now in the middle of wizarding up a Technology, Law and Society Summer Institute. With 5 graduate students representing fields from anthropology to computer science, we are mapping the landscape of law and technology, brainstorming about curriculum and trainings (maybe everyone should learn to program a Twitter bot!), and imagining paradigm shifts in the social study of law and technology.
When an AI creates a Lo-Fi Black Metal tune—and it’s both “convincing” and “potentially enjoyable,” while Forbes wonders about AI’s civil rights—do we have to start rethinking property? The legal profession itself is coming to grips with the impact of automation, “legal tech,” “regtech,” and lawyer bots. Not to mention of course the impact on the political sphere caused by Twitter-bots of Russian origin to influence voter opinion. How can sociolegal and STS scholars work together with computer scientists to anticipate and address what’s already happening in law-in-computation, to say nothing of its possible futures? Over a series of blog posts by our graduate student fellows, we will provide some examples of our research and thinking as we lead up to the summer institute.

1 Trackback